Unstructured text analysis in Relative Insight: how it works

Text analytics is the future of business intelligence. Relative Insight’s unstructured text analysis platform helps organizations capture insights from qualitative data at scale. While numbers can tell you what is happening, our comparative approach helps unearth the how and why so you can take informed actions.
But we often get asked – how does it all work? In this article, we demystify the inner workings of Relative Insight, helping you understand what happens once data is uploaded to the platform.
Natural language processing
Natural language processing (NLP) is a branch of AI that helps computers make sense of text. When an unstructured data set is fed into Relative Insight, the text flows through a series of processes – the NLP pipeline. As the data passes through the pipeline, it is transformed into something a computer can understand.
In essence, Relative Insight’s algorithms ‘read’ the text and record the linguistic features to enable further analysis of the data.
Key processes in the NLP pipeline include:
- Breaking the text down into sub-components (sentences, phrases, words)
- Labelling parts of speech (noun, pronoun, adjective, determiner etc.)
- Identifying named entities (people, locations, companies etc.)
- Topic Identification – the process of the computer recording what the text is about (the meaning)
The NLP pipeline also considers the fact that words can take on context-specific meanings. Think of the word spring which can be a body of water, season, mechanical component or verb. Because of this inherent quality of language, semantic tagging requires consideration of the words being used in conjunction with a linguistic feature to determine the meaning.
Meaning is assessed by using knowledge graphs – databases that inform the algorithms about the relationships between different concepts. These knowledge graphs are continuously updated using machine learning to improve the accuracy of classification over time.
A comparative approach to unstructured text analysis
After passing through the NLP pipeline, the platform stores a record of the frequencies of each identified linguistic feature. At this point, the data is ready for comparison!
To ensure an ‘apples to apples’ comparison, the platform first calculates the relative frequency of each linguistic feature. Relative frequency is a normalized frequency value that allows you to compare unequally sized data sets without distorting the analysis.
For example, if the word ‘beauty’ appears 5 times in a data set of 1,000 words this will have the same relative frequency as a 2,000-word data set where the word appears 10 times.
Once this is done, the relative frequencies for each linguistic feature are compared to determine the relative difference. Relative difference is calculated for each data set being compared:
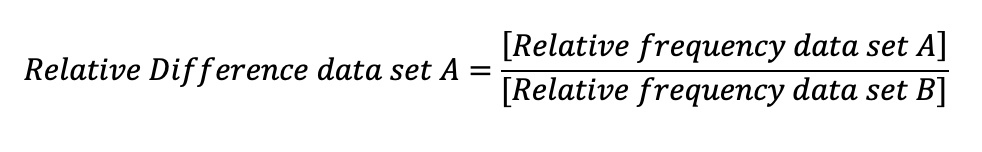
Based on this calculation, a particular linguistic feature can be classified as a difference, similarity or neither.
Differences
A relative difference of 1.0 indicates an equal prevalence of a particular linguistic feature. When relative difference values exceed 1.0 this indicates the linguistic feature is more prevalent in the data set being examined compared to others. The higher the value the bigger the difference.
To ensure there is sufficient evidence to assert a difference is not just happening by chance, the platform calculates the probability that the relative difference would indicate a difference where one doesn’t truly exist. This is done by looking at the probability distributions of the linguistic features in a dataset, and testing the ‘goodness of fit’ between the models that power Relative Insight and the data being analyzed.
Similarities
When a linguistic feature returns a relative difference between 0.9 and 1.1 and does not meet the threshold for classification as a difference, this indicates a potential similarity.
Function words (e.g. if, the, and) are removed as these words occur with a high frequency in any data set. Given these words do not convey meaning by themselves, they are not typically insightful.
As with differences, a statistical test is conducted to assess that a similarity wasn’t identified where one doesn’t truly exist before presenting the results in the platform.
Qualitative text analysis at scale
Through the combination of the NLP pipeline and comparison, Relative Insight’s unstructured text analysis engine surfaces the differences and similarities between data sets. This approach reveals the things that matter within the texts without having to labour through reading them manually. Once the algorithms have fired away, you can explore the results of the analysis, build insights cards and visualize groups of comparisons using Heatmaps.
Interested in learning more about unstructured text analysis? Watch our webinar with Relative Insight’s Head of Natural Language Processing Ryan Callihan.